Crear relaciones en base de datos
Imprimir
Este video te puede ayudar a construir las relaciones en tu base de datos.

Imprimir
Este video te puede ayudar a construir las relaciones en tu base de datos.
Imprimir
A la hora de crear un campo en una tabla, hay que especificar de qué tipo son los datos que se van a almacenar en ese campo.
Los diferentes tipos de datos de Access son:
Texto: cuando en el campo vamos a introducir texto, tanto caracteres como dígitos. Tiene una longitud por defecto de 50 caracteres, siendo su longitud máxima de 255 caracteres.
Memo: se utiliza para textos extensos como comentarios o explicaciones. Tiene una longitud fija de 65.535 caracteres.
Numérico: para datos numéricos utilizados en cálculos matemáticos.
Fecha/Hora: para la introducción de fechas y horas desde el año 100 al año 9999.
Moneda: para valores de moneda y datos numéricos utilizados en cálculos matemáticos en los que estén implicados datos que contengan entre uno y cuatro decimales. La precisión es de hasta 15 dígitos a la izquierda del separador decimal y hasta 4 dígitos a la derecha del mismo.
Autonumérico: número secuencial (incrementado de uno a uno) único, o número aleatorio que Microsoft Access asigna cada vez que se agrega un nuevo registro a una tabla. Los campos Autonumérico no se pueden actualizar.
Sí/No: valores Sí y No, y campos que contengan uno de entre dos valores (Sí/No, Verdadero/Falso o Activado/desactivado).
Objeto OLE: Objeto (como por ejemplo una hoja de cálculo de Microsoft Excel, un documento de Microsoft Word, gráficos, sonidos u otros datos binarios).
Hipervínculo: Texto o combinación de texto y números almacenada como texto y utilizada como dirección de hipervínculo. Una dirección de hipervínculo puede tener hasta tres partes:
Texto: el texto que aparece en el campo o control.
Dirección: ruta de acceso de un archivo o página.
Subdirección: posición dentro del archivo o página.
Sugerencia: el texto que aparece como información sobre herramientas.
Existe otra posibilidad que es la Asistente para búsquedas que crea un campo que permite elegir un valor de otra tabla o de una lista de valores mediante un cuadro de lista o un cuadro combinado. Al hacer clic en esta opción se inicia el Asistente para búsquedas y al salir del Asistente, Microsoft Access establece el tipo de datos basándose en los valores seleccionados en él.
Imprimir
aquí esta otro video para que inicies con la creacion de algunas tablas.
Imprimir
Si el maestro no se expreso en el aula, o disidiste no ponerle atencion aquí está un link que te puede ayudar.
Imprimir
La programación por capas es un estilo de programación en el que el objetivo primordial es la separación de la lógica de negocios de la lógica de diseño; un ejemplo básico de esto consiste en separar la capa de datos de la capa de presentación al usuario.
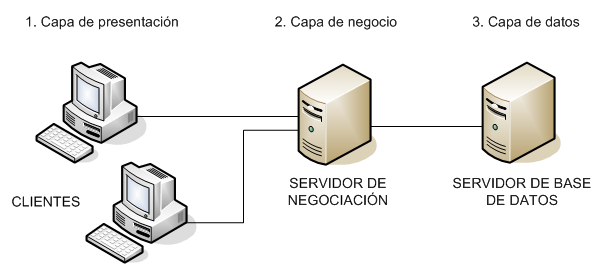
Imprimir
Hay tres características importantes inherentes a los sistemas de bases de datos: la separación entre los programas de aplicación y los datos, el manejo de múltiples vistas por parte de los usuarios y el uso de un catálogo para almacenar el esquema de la base de datos. En 1975, el comité ANSI-SPARC (American National Standard Institute - Standards Planning and Requirements Committee) propuso una arquitectura de tres niveles para los sistemas de bases de datos, que resulta muy útil a la hora de conseguir estas tres características.
El objetivo de la arquitectura de tres niveles es el de separar los programas de aplicación de la base de datos física. En esta arquitectura, el esquema de una base de datos se define en tres niveles de abstracción distintos:

Concepto | Wikipedia | Otro | Esquema |
|---|---|---|---|
Modelo de base de datos | Técnicas son usadas para modelar la estructura de datos. | Es una colección de herramientas conceptuales para describir los datos, las relaciones que existen entre ellos, semántica asociada a los datos y restricciones de consistencia. | - - - - - - - - - - - - - |
Modelo de red | Organiza datos que usan dos fundamental construcciones, registros llamados y conjuntos. Los registros contienen campos. Los conjuntos se definen de uno a varios relaciones entre registros: un propietario, muchos miembros. Un registro puede ser un propietario en cualquier número de conjuntos, y un miembro en cualquier número de conjuntos. Es una variación sobre el modelo jerárquico, al grado que es construido sobre el concepto de múltiples ramas emanando de uno o varios nodos, mientras el modelo se diferencia del modelo jerárquico en esto las ramas pueden estar unidas a múltiples nodos. | En este modelo las entidades se representan como nodos y sus relaciones son las líneas que los unen. En esta estructura cualquier componente puede relacionarse con cualquier otro. A diferencia del modelo jerárquico, en este modelo, un hijo puede tener varios padres. Los conceptos básicos en el modelo en red son:
| 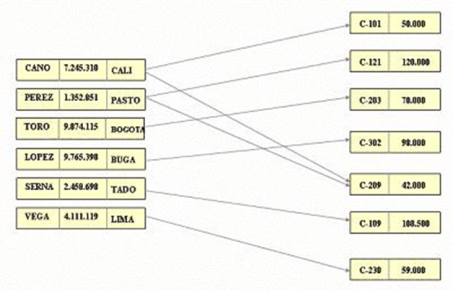 |
Modelo jerárquico | En un modelo jerárquico, los datos son organizados en una estructura parecida a un árbol, implicando un eslabón solo ascendente en cada registro para describir anidar, y un campo de clase para guardar los registros en un orden particular en cada lista de mismo-nivel. Esta estructura permite un 1:N en una relación entre dos tipos de datos. Esta estructura es muy eficiente para describir muchas relaciones en el verdadero real; recetas, índice, ordenamiento de párrafos/versos, alguno anidó y clasificó la información. En la relación Padre-hijo: El hijo sólo puede tener un padre pero un padre puede tener múltiples hijos. Los padres e hijos son atados juntos por eslabones "indicadores" llamados. Un padre tendrá una lista de indicadores de cada uno de sus hijos. | Este modelo utiliza árboles para la representación lógica de los datos. Este árbol esta compuesto de unos elementos llamados nodos. El nivel más alto del árbol se denomina raíz. Cada nodo representa un registro con sus correspondientes campos. La representación gráfica de este modelo se realiza mediante la creación de un árbol invertido, los diferentes niveles quedan unidos mediante relaciones. | 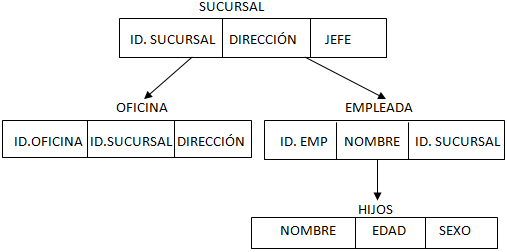 |
Modelo Entidad-Relación | El Modelo Entidad-Relación, también conocido como DER (diagramas entidad-relación) es una herramienta de modelado para bases de datos, mediante el cual se pretende 'visualizar' los objetos que pertenecen a la Base de Datos como entidades las cuales tienen unos atributos y se vinculan mediante relaciones. Es una representación conceptual de la información. Mediante una serie de procedimientos se puede pasar del modelo E-R a otros, como por ejemplo el modelo relacional. El modelado entidad-relación es una técnica para el modelado de datos utilizando diagramas entidad relación. No es la única técnica pero sí la más utilizada. Brevemente consiste en los siguientes pasos:
| Denominado por sus siglas como: E-R; Este modelo representa a la realidad a través de entidades, que son objetos que existen y que se distinguen de otros por sus características. Las entidades pueden ser de dos tipos:
| |
Modelo relacional | El modelo relacional fue presentado como un modo de hacer sistemas de gestión de datos más independientes de cualquier uso particular. Esto es un modelo matemático definido en términos de predicado lógico y la teoría de juego. Tres términos clave son usados extensivamente en el Modelo Relacional: relaciones, atributos, y dominios. Una relación, figurativamente hablando, es una tabla con columnas y filas. El atributo, es un descriptor de la relación, figurativamente hablando, sería el encabezado de cada una de las columnas de la tabla. El dominio de un atributo es el conjunto de valores legales que puede tomar el atributo. La estructura de datos básica del modelo relacional es la tabla, donde la información sobre una entidad particular (decir, un empleado) es representado en columnas y filas (también llamado tuplas). Así, "la relación" en "la base de datos relacionada" se refiere a varias tablas en la base de datos; una relación es un juego de tuplas. Las columnas enumeran varios atributos de la entidad (el nombre del empleado, la dirección o el número de teléfono, por ejemplo), y una fila es un caso real de la entidad (un empleado específico) que es representado por la relación. Por consiguiente, cada tupla de la tabla de empleado representa varios atributos de un empleado solo. Todas las relaciones (y tablas) en una base de datos relacionada tienen que adherirse a algunas reglas básicas de licenciarse como relaciones. Primero, el ordenamiento de columnas es inmaterial en una tabla. Segundo, no puede haber tuplas idénticas o filas en una tabla. Y tercero, cada tuple contendrá un valor solo para cada uno de sus atributos. Una base de datos relacional contiene múltiples tablas, cada similar al que en el modelo de base de datos "plano". Una de las fuerzas del modelo relacional es que, en principio, cualquier valor que ocurre en dos registros diferentes (perteneciendo a la misma tabla o a tablas diferentes), implica una relación entre aquellos dos registros. Una llave que puede ser usada únicamente identificar una fila en una tabla una llave primaria. Las llaves comúnmente son usadas unir o combinar datos de dos o más tablas. Por ejemplo, una tabla de Empleado puede contener una columna la Ubicación llamada que contiene un valor que empareja la llave de una tabla de Ubicación. Las llaves son también críticas en la creación de índices, que facilitan la recuperación rápida de datos de mesas grandes. Cualquier columna puede ser una llave, o múltiples columnas pueden ser agrupadas juntos en una llave compuesta. No es necesario definir todas las llaves por adelantado; una columna puede ser usada como una llave incluso si al principio no fue querido para ser el que. Una llave externa que tiene un significado en el mundo real (como el nombre de una persona, ISBN de un libro, o el número de serie de un coche) es una llave "natural". Si ninguna llave natural es conveniente (pensar en mucha gente elnombre José), un a llave arbitraria o sustituta puede ser asignada (como dando a empleados numeros ID). En la práctica, la mayor parte de bases de datos han generado ambas y llaves naturales, porque las llaves generadas pueden ser usadas internamente crear eslabones entre las filas que no pueden romperse, mientras llaves naturales pueden ser usadas, menos de fuentes fidedignas, para búsquedas y para la integración con otras bases de datos. (Por ejemplo, los registros en dos bases de datos por separado desarrolladas podrían ser correspondidos por el número de la Seguridad Social, excepto cuando los números de la Seguridad Social son incorrectos, la omisión(la acción de echar de menos), o se han cambiado). | Este modelo es el más utilizado actualmente ya que utiliza tablas bidimensionales para la representación lógica de los datos y sus relaciones. Algunas de sus principales caracteristicas son:
El elemento principal de este modelo es la relación que se representa mediante una tabla. |  |
Imprimir
Después de su invetigación compararemos los resultados con dos fuentes más.
Conceptos Básicos | ||
| Base de Datos. (DB) | Almacén de datos relacionados con diferentes modos de organización. Una base de datos representa algunos aspectos del mundo real, aquellos que le interesan al diseñador. Se diseña y almacena datos con un propósito específico. Las bases de datos almacenan datos, permitiendo manipularlos fácilmente y mostrarlos de diversas formas. | Conjunto de datos relacionados que se almacenan de forma que se pueda acceder a ellos de manera sencilla, con la posibilidad de relacionarlos, ordenarlos en base a diferentes criterios. Las bases de datos son uno de los grupos de aplicaciones de productividad personal más extendidos. |
| Dato | Representación simbólica (numérica, alfabética, etc.) de un atributo de una entidad. Un dato no tiene valor semántico (sentido) en sí mismo, pero al ser procesado puede servir para realizar cálculos o tomar decisiones. | Unidad mínima de información, sin sentido en sí misma, pero que adquiere significado en conjunción con otras precedentes de la aplicación que las creó. Conjunto de simbolos que unidos de cierta forma dan un significado querente y lógico. |
| Campo | En informática, espacio para el almacenamientode un dato en particular. En las bases de datos un campo es la mínima unidad de almacenamiento de información accesible. En las hojas de cálculo los campos son llamados celdas. Los campos suelen tener asociados un tipo de dato que permiten almacenar. | Es el espacio reservado para introducir determinados datos asociados a una categoría de clasificación. |
| Registro | Es un conjunto de campos relacionados que constituyen la base de la información. En la cual un fichero de datos relacionales se denomina tabla, los registros son cada una de sus filas. | Es una unidad de almacenamiento destinada a contener cierto tipo de datosde dirente tipo de dato. |
Tablas | Contenedor de datos que almacenalainformcion y filas(registros) y columnas (campos). Una o más filas de celdas de una página que se utilizan para organizar datos sistemáticamente. | Es un objeto, o una entidad que se identifica a travez de sus atributos campos (columnas), y puede ser la abstraccion de algo real o intangible. |
| Relaciones. | Vínculo entre dos o más entidades describe algúna interacción entre las mismas. Por ejemplo, una relación entre una entidad "Empleado" y una entidad "Sector" podría ser "trabaja_en", porque el empleado trabaja en un sector determinado. | Vínculo entre dos o más entidades describe alguna interacción entre las mismas. Las relaciones son muy empleadas en los modelos de bases de datos relacional y afines. |
Consultas | Es el método para acceder a los datos en las bases de datos. Con las consultas se puede modificar, borrar, mostrar y agregar datos en una base de datos. | Permite explorar datos almacenados en labase de datos con el objetivo de recuperar cierta informacion. |
| Formularios | Un documento con espacios (campos) en donde se pueden escribir o seleccionar opciones. Cada campo tiene un objetivo, por ejemplo, el campo "Nombre" se espera que sea llenado con un nombre, el campo "año de nacimiento", se espera que sea llenado con un número válido para un año, etc. | Es una herraienta util para ver e insertar datos. permite capturar datos de forma censilla. |
| Informe | Es una manera personalizada de presentar datos impresos que contiene la base de datos. | - - - - - - - - - - -- - - - - - - |
Sistemas Gestores de Base de Datos (SGBD) | Son un tipo de software muy específico, dedicado a servir de interfaz entre la base de datos, el usuario y las aplicaciones que la utilizan. | Se trata de un conjunto de programas que se encargan de la privacidad, la integridad, la seguridad de los datos y la interacción con el sistema operativo. Proporciona una interfaz entre los datos, los programas que los manejan y los usuarios finales. |
Imprimir
Fuentes de información recomendadas por el Departamento de Bachillerato General
Conceptos generales.
Imprimir
Este video muestra un pequeño ejemplo del uso de las bases de datos y a importancia de tenerlo actualizado.
Durante la clase abordaremos algunos ejemplos como este.
La Importancia de las Bases de Datos en la Toma de Decisiones
Las bases de datos, hoy en día, ocupan un lugar determinante en cualquier área del quehacer humano, comercial, y tecnológico. No sólo las personas involucradas en el área de Informática, sino todas las personas administrativas, técnicas y con mayor razón los profesionales de cualquier carrera, deben de tener los conocimientos necesarios para poder utilizar las bases de datos.
Ninguna empresa existiría si no tuviera clientes que atender; por ello, miles de empresas en el mundo dedican gran parte de su tiempo y esfuerzo a tratar de incrementar el número de retención de clientes y su grado de satisfacción.
Rapp y Collins en su libro "Maximarketing" recuerdan que si las instalaciones, maquinaria, herramientas e inventarios de su empresa quedarán destruidas por un incendio pero usted fuese dueño de un producto o un servicio en el cual el mercado confiara, usted seguiría contando con un activo sumamente valioso, y si hubiera guardado en su caja fuerte a prueba de incendios una copia de su base de datos con los nombres y direcciones de todos sus buenos clientes, sería dueño también de otro activo fundamental, quizás de igual valor.
Crear y mantener actualizada la base de datos le puede ser muy útil para conservar la lealtad de sus clientes. Pero cuidado no confunda un simple listado de clientes con una base de datos. La base de datos es un archivo computarizado de nombres, a los cuales se le vinculan otras variables de información, mediante la cual pueda realizarse una selección o una segmentación. De acuerdo a estos mismos autores el poder de una buena base de datos puede llevar a una organización a:
1. Maximizar las ventas repetitivas.
2. Maximizar la lealtad de los clientes.
3. Maximizar las promociones.
4. Maximizar la ampliación de líneas de productos o servicios.
5. Maximizar el éxito en nuevas empresas.
Access 2007
Asegurar que podemos identificar a nuestros mejores clientes y darles un trato diferencial nos ayuda a desarrollar su lealtad. Si el cliente se siente bien atendido es menos probable que busque otro proveedor y actualmente la retención de clientes es un factor importante en las utilidades de las empresas
Así mismo, conocer a los clientes y saber sus preferencias es un recurso vital en el desarrollo de productos y estrategias de ventas. Poder conocer con exactitud los datos básicos de segmentación del cliente (sexo, edad, preferencias básicas, etc.) y tal vez poder ir más allá en el conocimiento (preferencias personales, aficiones, gustos básicos, marcas preferidas) resultan recursos muy valiosos para las empresas. Los datos recogidos de los clientes, formarán bases de clientes, de usuarios registrados y de posibles compradores, quienes serán susceptibles de recibir información actualizada de productos y servicios ofrecidos.
En este entorno, la recopilación de bases de datos servirá a las empresas para:
1. Mantener comunicación constante con los clientes (mail, teléfono, correo, etc.)
2. Conocer las tendencias de compra del mercado objetivo.
3. Personalizar la atención a los usuarios. Es importante destacar que la "personalización", es considerada como la quinta P en la mezcla de mercadotecnia.
4. Generar estrategias de branding y publicidad. Cuando estamos ofreciendo, estamos generando publicidad constante al mismo tiempo.
5. Utilizar segmentos específicos de clientes para colocar productos específicos llegando de manera directa al comprador o usuario.
6. Comentar las novedades, promociones y noticias relacionadas con el negocio y en algunas ocasiones con el sector al que se dedica la empresa.
Para poder usar las bases de datos debemos conocer una herramienta que nos permita, almacenar y consultar información estas herramientas son llamadas sistemas de gestión de base de datos (SGBD).
Imprimir
Unidad_1 Introducción a las bases de datos 15 hrs.
1.1 Conceptos básicos.
1.1.1 Base de datos.
1.1.2 Dato, campo y registro.
1.1.3 Tablas, Claves y relaciones.
1.1.4 Consultas y formularios.
1.1.5 Informes y reportes.
1.1.6 Tipos de Gestores de base de datos.
1.2 Modelos de base de datos.
1.2.1 Modelos de bases de datos.
1.2.2 Modelo de red.
1.2.3 Modelo jerárquico.
1.2.4 Modelo entidad-relación.
1.2.5 Modelo relacional.
1.3 Requerimientos de construcción.
1.3.1 Modelo ANSI PARK.
1.3.2 Arquitectura de 3 niveles.
1.4 Álgebra relacional.
1.4.1 Operadores primitivos.
1.4.2 Operadores derivados
1.4.3 Operadores adicionales de consulta
Unidad_2 Organización de Bases de datos. 26 hrs.
2.1 Tablas.
2.1.1 Diseño de tablas.
2.1.2 Operaciones Principales
2.1.3 Definición de claves.
2.1.4 Relación de tablas.
2.2 Formularios
2.2.1 Creación de formularios
2.2.2 Modificar un formulario
2.2.3 Agregar objetos a un formulario
2.3 Consultas
2.3.1 Consultas por asistente
2.3.2 Consultas por varias tablas
2.3.3 Consultas por parámetros
2.4 Informes
2.4.1 Partes de un informe
2.4.2 Creación de un informe utilizando el asistente.
2.4.3 Creación de un informe utilizando tablas.
Unidad_3 Ciclo de vida y normalización de un sistema de base de datos. 16 hrs.
3.1 Normalización
3.1.1 Primera forma normal.
3.1.2 Segunda forma normal.
3.1.3 Tercera forma normal.
3.2 Ciclo de vida del sistema de aplicación de base de datos.
3.2.1 Recolección y análisis de información
3.2.2 Diseño conceptual de la base de datos.
3.2.3 Elección de un sistema gestor de base de datos.
3.2.4 Transformación al modelo de datos.
3.2.5 Diseño físico de la base de datos.
3.2.6 Generación de un sistema de base de datos.